随着AI、HPC的快速增长,GPU加速计算已经成为推动科学发展的关键力量,在天文学、物理学等研究领域,GPU加速的AI正在帮助科学家们解决前所未有的复杂问题。

与CPU相比,GPU在设计上更擅长处理大量并行任务,这使得它们在执行计算密集型任务时表现的更出色。今天我们从GPU的运作机制和设计原理来聊聊为什么GPU在并行计算的时候更高效。
处理器的三个组成部分
我们知道,任何处理器内部都是由三部分组成,分别为算术逻辑单元(ALU)、控制单元和缓存。但CPU(Central Processing Unit)和GPU(Graphics Processing?Unit)是两种不同类型的计算机处理器。

简单来说,CPU更善于一次处理一项任务,而且GPU则可以同时处理多项任务。这是因为CPU是为延迟优化的,而GPU则是带宽优化的。就好比有些人善于按顺序一项项执行任务,有些人可同时进行多项任务。
我通过打比方来通俗的解释二者的区别。CPU就好比一辆摩托车赛车,而GPU则相当于一辆大巴车,如果二者的任务都是从A位置将一个人送到B位置,那么CPU(摩托车)肯定会更快到达,但是如果将100个人从A位置送到B位置,那么GPU(大巴车)由于一次可以运送的人更多,则运送100人需要的时间更短。

换句话说,CPU 单次执行任务的时间更快,但是在需要大量重复工作负载时,GPU 优势就越显著(例如矩阵运算:(A*B)*C)。因此,虽然CPU单次运送的时间更快,但是在处理图像处理、动漫渲染、深度学习这些需要大量重复工作负载时,GPU优势就越显著。
综上所述,CPU 是个集各种运算能力的大成者。它的优点在于调度、管理、协调能力强,并且可以做复杂的逻辑运算,但由于运算单元和内核较少,只适合做相对少量的运算。GPU 无法单独工作,它相当于一大群接受 CPU 调度的流水线员工,适合做大量的简单运算。CPU 和 GPU 在功能上各有所长,互补不足,通过相互配合使用,实现最佳的计算性能。
那么是什么导致CPU和GPU工作的方式不同呢?那还要从二者设计理念来说。
FLOPS并不是核心问题?
FLOPS每秒浮点运算次数(FLoating point Operations Per Second,简称 FLOPS)是基于处理器在一秒内可以执行的浮点算术计算数量,经常用来来衡量计算机性能的指标。虽然大家常问一个设备的FLOPS是多少,但实际上这并不是一个核心问题。

我们可以换一种说话,就是虽然有一些专家或特定算法的时候会特别关注FLOPS。但FLOPS其实并不是大众关心的焦点。

为什么会这样说呢?我们以上图为例,让我们看一下CPU的运行情况:CPU能以大约2000 GFLOPs FP64的速度进行运算,但内存却只能以200 GB/s的速度向CPU提供数据,这是现代处理器的典型性能。于是当CPU想要每秒处理2万亿个双精度数值,但内存每秒只能提供250亿个。这个时候就会产生设备的“计算强度”不平衡,这个时候就需要CPU设备需要付出多少努力来弥补内存提供数据的速度不足。
否则,处理器就会因为闲置造成浪费,陷入所谓的“内存带宽限制”模式。事实上,至少有四分之三甚至更多的程序在实际运行中都会受到内存带宽的限制,因为很少有算法能在每次数据加载时完成足够多的运算来充分利用硬件性能。这时购买更便宜的CPU或许更为合适。
这种高计算强度要求对于大多数算法来说都是难以达到的。实际上,只有矩阵乘法这类特殊算法能满足这一要求。接下来我们看下GPU是怎么来弥补这个计算强度的。

通过上面的表格,我们对比GPU和CPU几个不同进程的性能。你会发现,虽然NVIDIA芯片拥有更高的FLOPS,但是他们计算强度几乎相同,这是因为NVIDIA配备了更高带宽的内存以保持平衡。
其实,每一代GPU在增加FLOPS方面的速度往往超过了增加内存带宽的速度。这导致计算强度不断上升,给算法编程带来了更大的挑战。这就需要GPU不断努力优化算法,以确保这些强大的芯片能够保持高效运行。因为很少有算法能在每次数据加载时完成足够多的运算来充分利用硬件性能。
当然,高内存支持和代码优化并不是GPU性能优势的全部,我们还需要看一下延迟。我们来深入谈谈延迟这个概念。为何延迟如此关键呢?
延迟,让我们通过一个时间线来直观理解。从最基础的运算操作来看:ax + y。首先,要加载变量x。接着,加载y。因为运算是a乘以x再加上y。所以,会同时发起对y的加载请求。然后,会经历一段相当长的等待时间,直到x的数据返回。这段时间往往是空闲的,也就是我们所说的延迟,这样就导致计算非常不高效。

虽然这个时间很短,也可能被其它有用的计算工作所掩盖,不会造成明显的延迟。但处理器编译器实际上花费了大量精力来进行流水线优化,确保数据加载尽可能早地发起,以便被其它计算操作所覆盖。这种流水线处理是大多数程序性能优化的关键,因为内存访问的延迟往往比计算延迟要大得多。

那么为什么会这样呢?
这是因为在一个时钟周期内,光只能传播很短的距离。考虑到芯片的尺寸,电信号从芯片的一侧传输到另一侧可能需要一个或多个时钟周期。因此,物理定律成为了限制性能的关键因素。尤其是当需要从内存中获取数据时,数据的往返传输可能就需要十到二十个时钟周期。
延迟就意味着花费了大量时间等待数据的到来。
在之前提到CPU经常处于空闲状态,因为内存延迟导致它无法保持忙碌。尽管CPU拥有强大的计算能力(即FLOPS),但我希望内存能够与之匹配,确保数据能够及时到达。

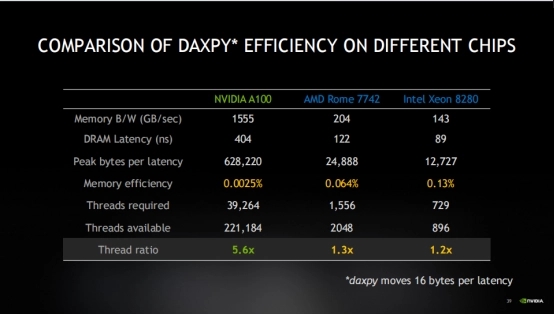
以Xeon 8280为例,这款CPU拥有131GB的内存和89纳秒的延迟。当内存带宽为131GB/s时候,那么在一个内存延迟周期内,只能移动约11659字节的数据。这似乎还不错,但当我们考虑到DAXPY操作只加载了两个8字节的值(即x和y),总共只有16字节时,效率就显得非常低下,仅为0.14%。这显然不是一个好的结果。即使有高带宽的内存来应对计算强度,实际上几乎没有利用到它的优势。为高性能的CPU和内存付出了巨大的成本,但结果却并不理想。

这是因为程序受到了延迟绑定的影响,这是一种常见的内存限制形式,其发生的频率远高于我们的想象。这也解释了为什么我对FLOPS并不太关心,因为即使内存带宽无法充分利用,计算单元更是无法忙碌起来。
如果我将11659字节的数据除以16字节(即DAXPY操作加载x和y所需的总字节数),发现需要同时执行729个DAXPY迭代,才能让花在内存上的钱物有所值。因此,面对这种低内存效率,需要同时处理729个操作。

这个时候,就需要并发来解决这个问题了。并发,顾名思义,就是同时进行许多事情。但请注意,这些操作不必是严格同时发生的,它们只需要能够独立进行。GPU编译器有一种优化手段叫做循环展开,它能够识别出可以独立执行的部分,并将它们连续地发出,从而提高执行效率。
但是在实际循环进行的优化方式受限于硬件能够同时跟踪的操作数量,几乎是不可能完成的。在硬件的流水线中,它只能同时处理有限数量的事务,超出这个数量就不得不等待之前的事务完成。因此,循环展开确实有益,它可以让流水线更加饱满,但显然它也受到机器架构中其它多种因素的制约。
这个时候,就需要看硬件的所能支持的最大线程数了,这意味着多个操作是真正同时发生的。GPU在这方面做了很好的支持。
线程在GPU中起到什么作用?
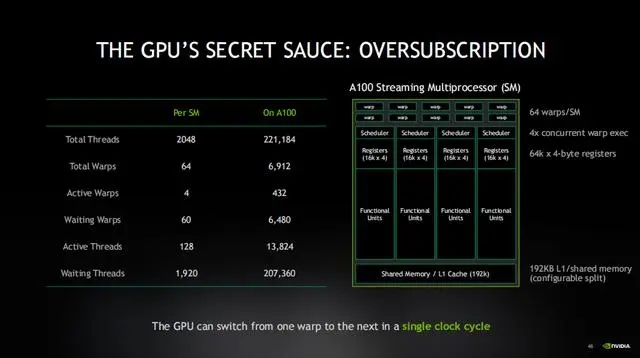
GPU与CPU之间一个非常值得关注的差异点,GPU的延迟和带宽要求比CPU高得多,这意味着它需要大约40倍的线程来弥补这种延迟。但实际上,GPU拥有的线程数量比其它类型的处理器多100倍。因此,在实际应用中,GPU的表现反而更好。

实际上,GPU拥有的线程数量比实际运算需要的多出五倍半,而其它类型的CPU,它们的线程数量可能只够覆盖1.2英寸范围内的操作,这就是GPU设计中最为关键的一点。如果你从这次讲解中只能记住一件事,那就是:GPU拥有大量的线程,远超过它实际需要的数量,这是因为它被设计为“超量订阅”(oversubscription)。它旨在确保有大量线程在同时工作,这样即使某些线程在等待内存操作完成,仍然有其它线程可以继续执行。
GPU通常被称为“吞吐量机器”。GPU的设计者将所有的资源都投入到了增加线程数量而不是减少延迟上。相比之下,CPU则更侧重于减少延迟,因此它通常被称为“延迟机器”。
CPU期望单个线程能够完成大部分工作。在CPU中切换线程(从一个线程切换到另一个线程)是一个资源消耗高的操作,它涉及到上下文切换,因此只需要足够多的线程来覆盖内存延迟即可。
所以,CPU的设计者将所有资源都投入到了减少延迟而不是增加线程数量上。
GPU和CPU在线程方面的解决方法是截然相反的,虽然它们都是用来解决相同的延迟问题,但实际上也是GPU和CPU在运行方式和工作原理上的根本差异所在。记住,GPU设计者通过增加线程数量来对抗延迟,而不是通过减少延迟来降低延迟。
另外,需要注意的是GPU是被超量订阅的。这意味着,当一些线程在等待读取数据时,其它线程已经完成了读取并准备执行。这就是GPU工作原理的关键所在。它可以在一个时钟周期内轻松地在不同的warp之间切换,因此几乎没有上下文切换的开销。它可以连续运行线程。这意味着,为了弥补延迟,GPU需要保持的活跃线程数要远远超过系统在任何时候能够运行的线程数。这与CPU的工作方式截然不同,对于CPU来说,它永远不希望线程过多。
除了线程上的不同,内存也是GPU工作的极为关键的因素,这是因为所有的编程工作都是围绕内存展开的。
GPU内存需要足够大
GPU为每个线程分配了大量的寄存器来存储实时数据,从而实现了非常低的延迟。这是因为与CPU相比,GPU中每个线程都需要处理更多的数据,因此它需要能够快速访问这些数据。所以,GPU需要一种靠近其计算核心的快速内存,并且这种内存需要足够大,以便能够存储进行有用计算所需的所有数据。
不仅如此,当你发出一个加载操作(比如将某个指针的值加载到变量x中)时,硬件需要一个地方来暂存这个加载结果。所以,当说从内存中加载数据时,我实际上是指将这个加载结果放入寄存器中,这样就可以对它进行计算了。而GPU所拥有的寄存器数量直接决定了它能够同时处理的内存操作数量。
GPU的主内存就是高带宽的HBM内存。如果我把GPU主内存的带宽看作一个单位,无论它有多快,都只能算作一。而L2缓存带宽则是它的五倍,L1缓存,也就是我即将提到的共享内存,更是快了13倍。因此,随着带宽的增加,它更容易满足计算强度的需求,这无疑是一件好事。如果可能的话,大家希望能充分利用缓存来满足计算强度。
我们再来看一下每个内存层在操作时所需的计算强度。对于HBM,我们之前看过的计算强度是100。而L2缓存的计算强度则要好得多,只需要39次加载操作,L1缓存更是只需要8次,这是一个非常可实现的数字。这就是为什么L1缓存、共享内存和GPU如此有用的原因,因为我实际上可以让数据足够接近计算核心,从而有意义地进行8次操作并充分利用FLOP。所以,如果可以的话,所有数据都能从缓存中读取带来的提升是最有价值的。
但是需要注意的是,PCIe的带宽很有限,延迟又很大。NVLink在性能上比PCIe更接近主内存。这也是为什么NVLink作为芯片之间和GPU之间的互连方式,比PCIe总线要好得多的原因。
通俗讲解GPU的工作原理
好了,看了上面复杂的内容,让我们来通过一些形象的例子来了解GPU的运作机制。首先我们来谈谈吞吐量和延迟。首先我们来打个比方,例如这个人住在旧金山,但在圣克拉拉工作。

这个时候这个人上班就有两种方式选择。可以开车,只需要45分钟,或者可以坐火车,需要73分钟。
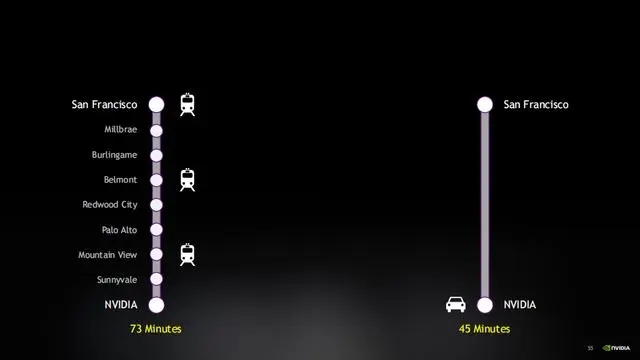
这个时候,汽车是为减少延迟而设计的,但火车是一个吞吐量机器。想象一下,开车的优势是在于它尽量快速地完成一次旅程,但并没有真正帮助到其他人。它速度快,但效率不高,只能载少数人,并且只能从一个地方到另一个地方。另一方面,火车可以载很多人,而且它能够在很多地方停靠,所以沿途的所有人都可以借助火车来上班。可而且设置很多列火车来运输乘客。
这个时候,火车不同班次就相当于GPU的延迟系统,被超量订阅,性能就会大打折扣。但如果路上的车太多,交通陷入瘫痪,汽车没人能顺利到达目的地。但同样,如果火车已经满员,你只需要等待下一班。而且,与汽车不同,火车晚点通常不会太久,因为总有下一班火车可以搭乘。
所以,GPU其实可以看作是一个吞吐量机器,它的设计初衷是能够处理比它一次运行的工作多得多的任务。这就像火车系统,如果火车没有满载,那就没有充分利用其运输能力。对于GPU来说也是如此,吞吐量系统通常希望有深度的等待队列。火车公司其实希望你在站台上等待,因为如果火车到站时站台上没有人,车厢没有满载,那他们就是在浪费资源。GPU也是如此,它需要保持忙碌状态,才能充分发挥其性能。
CPU则更偏向于一个延迟机器。切换线程需要消耗资源,所以CPU希望每个线程都能尽快完成其任务。但如果任务太多,系统就会陷入停滞。因此,CPU的目标是尽快完成每个任务,然后为下一个任务腾出空间。这就像我们希望车辆在路上畅通无阻,而不是停滞不前,因为道路上的车辆数量是有限的。简而言之,我们利用这些线程来解决延迟问题,这是一个非常有效的策略。
现在我们已经了解了延迟问题,接下来看看带宽的挑战。由于整个系统都是基于吞吐量的设计,GPU通常会超量订阅资源。这意味着GPU总是有任务在执行,内存也在不断地被访问。
在这个过程中,我们必须考虑异步性。很重要的一点是,CPU和GPU是独立的处理器,这意味着它们可以同时处理不同的任务,而且应该这样做。如果CPU停下来等待GPU,或者GPU停下来等待CPU,那么整个系统的效率就会下降。这就像每个站点都要等待下一班火车才能继续前行,这样显然不如只有一个高效的处理器。
异步性的重要性在于它让所有的处理器都在工作,没有人停下来等待。CPU可以向GPU发送工作指令,然后继续执行其它任务,而GPU则独立地处理这些任务。我们只需要等待最终的结果。

为了更形象地解释这个概念,我们可以想象一下道路交通。如果你想一次性移动很多东西,那么你需要更多的车道,就像右边的道路一样。这样的交通是异步的,每个车辆都可以独立地前进,不会被前面的车辆阻塞,因为车道足够多。相反,如果交通是同步的,那么只有一条车道,所有的车辆都必须等待最慢的那辆车,效率就会大打折扣。因此,异步性对于我们追求的高吞吐量至关重要。
然而,在现实世界中,很少有工作是完全独立的。DAXPY就是一个很好的例子。这些被称为逐元素(element-wise)算法,只有最简单的算法才能以这种方式工作。大多数算法至少需要一个或多个元素,比如卷积操作,它会考虑图像中的每个像素及其邻居。还有一些算法,如傅里叶变换,需要每个元素与其它每个元素进行交互。这些被称为全对全算法,它们的行为方式与逐元素算法截然不同。
GPU工作中是如何获取吞吐量的?
现在,让我们一起看下GPU上并行处理的工作原理,以及GPU是如何获得所需的吞吐量的。

我们假设训练了一个AI来识别互联网上的猫。现在,我们有一张猫的图片。我会在这张图片上覆盖一个网格,这个网格将图片分割成许多工作块。然后,我会独立地处理每个工作块。这些工作块是彼此独立的,它们在图片的不同部分工作,而且工作块的数量非常多。因此,GPU会被这些工作块过度订阅。但请记住,过度订阅是我们追求高效执行和最大内存使用的一种策略。

在每个工作块中,都有许多线程共同工作。这些线程可以共享数据并完成共同的任务。所有的线程都同时并行运行,这样GPU就能够实现高效的并行处理。现在,已经构建了层次结构。在最高层,有总工作量,它通过网格被分解成工作块,这些工作块为GPU提供了所需的过度订阅。然后,在每个工作块中,有一些本地线程,它们一起协同工作。通过这种方式,能够充分利用GPU的并行处理能力,实现高效的吞吐量。

当我们训练了一个AI来处理图像。这些线程协同工作,它们在各自的分片(tile)上工作,组成一个个块。请记住,每个块都以自己的速度独立运行,最终,整个图像会被处理完成。
在GPU上,工作是以网格的形式运行的,这些网格进一步被分解成线程块。每个块都拥有并行运行的线程,确保它们能够同时处理任务并共享数据。然而,所有的块都是独立调度的,这种模式被称为过度订阅。

这带来了两种最佳的运算的结合。它既能保持机器的忙碌状态,又能够提供所需的吞吐量,同时还允许线程之间进行必要的交互。这就是GPU编程的精髓:将问题分解成多个块,在这些块中,协作的线程共同处理任务,且每个块都保持着相对的独立性。

好吧,就到这里吧,我们我们已经详细介绍了GPU的工作原理,延迟被超量订阅所掩盖,但其实延迟实际上是GPU取得成功的关键。所有这些——大量的线程、超量订阅、网格和块的编程模型,以及在块中运行的线程——它们都是为了对抗延迟而存在的。如今NVIDIA GPU已经做到了,并且取得了成功,但现在我们受到了带宽的限制,这是接下来NVIDIA研发的重点。